|
I am currently a final-year DPhil (PhD) student at Visual Geometry Group (VGG), University of Oxford, advised by Prof. Andrew Zisserman and Prof. Weidi Xie. During Summer 2025, I interned at Google DeepMind London as a student researcher, working on dense video perception and 4D reconstruction. Prior to that, I completed my undergraduate studies at University of Cambridge and received MSc and BA degrees in Natural Sciences (Physics), during which I did summer interns on machine learning and physics at Caltech, Fudan University, and University of Cambridge. |

|
|
My research focuses on understanding motion and interactions in video, including multi-modal video understanding, dense motion understanding, and object-centric learning. |
|
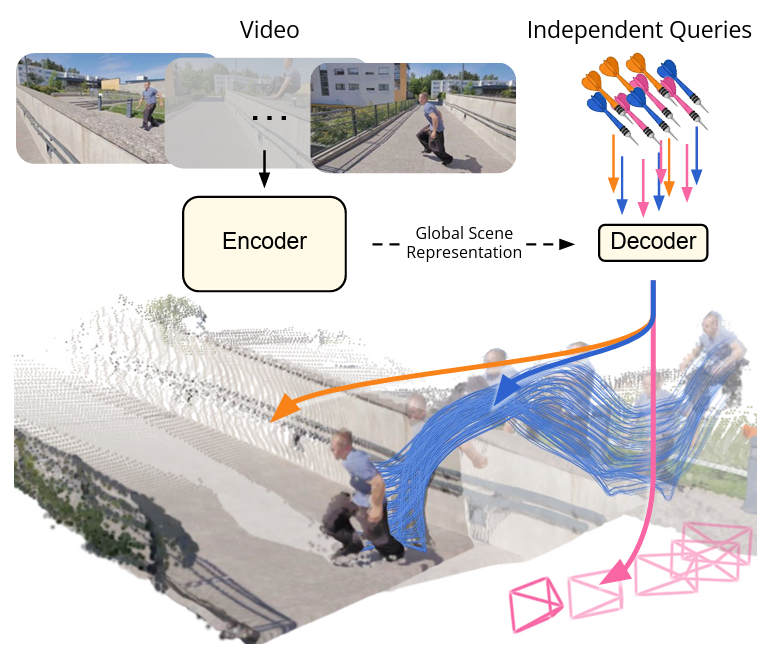
Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ignacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Joëlle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, Mehdi S. M. Sajjadi ArXiv, 2025 ArXiv / Bibtex / Project page D4RT is a feedforward model that utilizes a unified transformer architecture and a novel querying mechanism to jointly infer depth, spatio-temporal correspondence, and camera parameters from a single video, achieving state-of-the-art performance in 4D reconstruction tasks. |
|
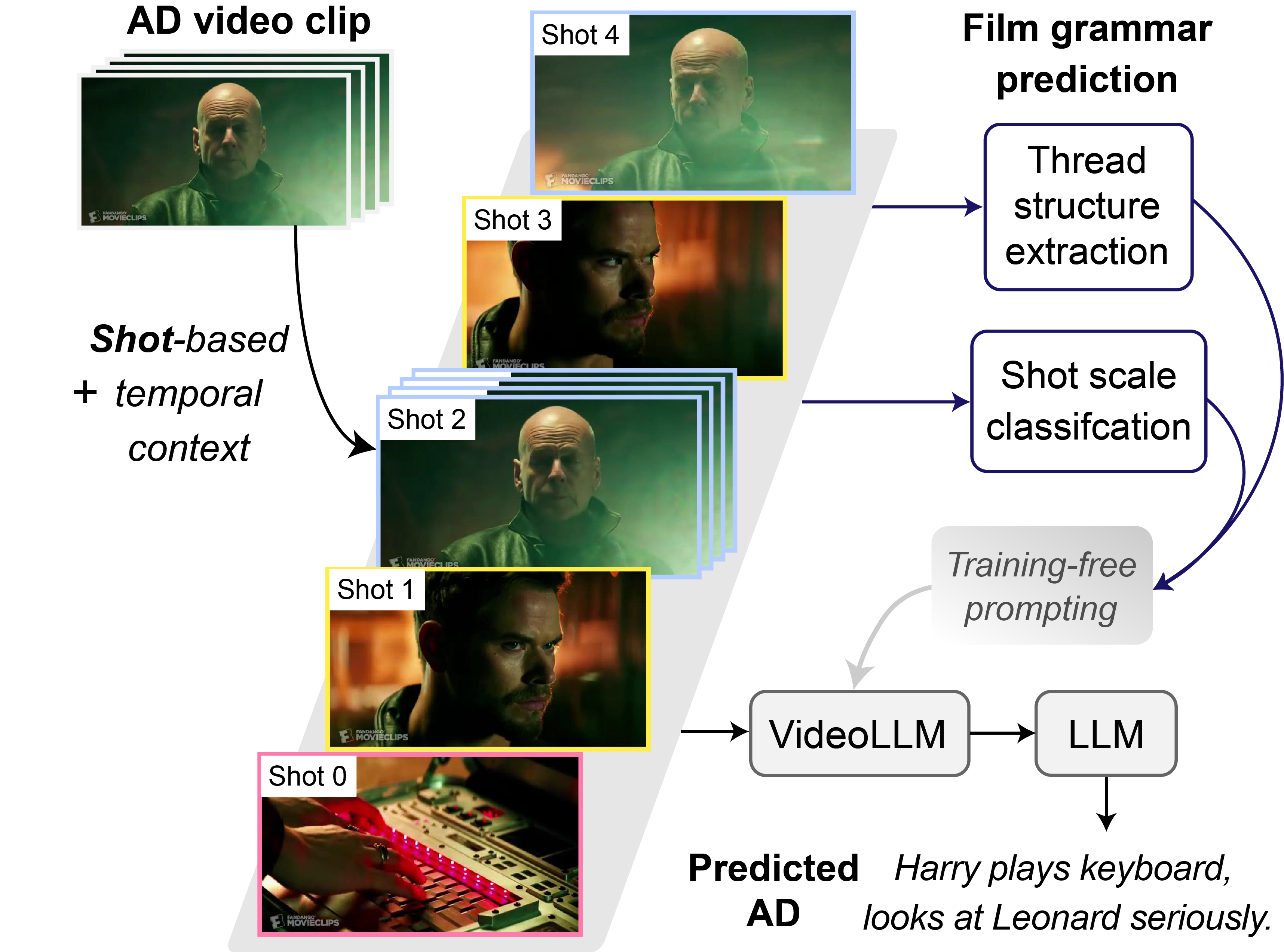
Junyu Xie, Tengda Han, Max Bain, Arsha Nagrani, Eshika Khandelwal, Gül Varol, Weidi Xie, Andrew Zisserman In ICCV, 2025 ArXiv / Bibtex / Project page / Code / Metric (Action Score) In this work, we introduce an enhanced two-stage training-free framework for Audio Description (AD) generation. We consider "shot" as the fundamental unit in movie and TV series, incorporating shot-based temporal context and film grammar information into VideoLLM perception. Additionally, we formulate a new metric (Action Score) that assesses whether the predicted ADs captures the correct action information. |

|
Zhongrui Gui, Junyu Xie, Tengda Han, Weidi Xie, Andrew Zisserman In ACMMM, 2025 ArXiv / Bibtex / Project page / Code To address the challenge of recognising highly variable animated characters, this work introduces a novel audio-visual pipeline and the CMD-AM dataset, utilising a multi-modal character bank to significantly improve accessibility through generated audio descriptions and character-aware subtitles. |
|
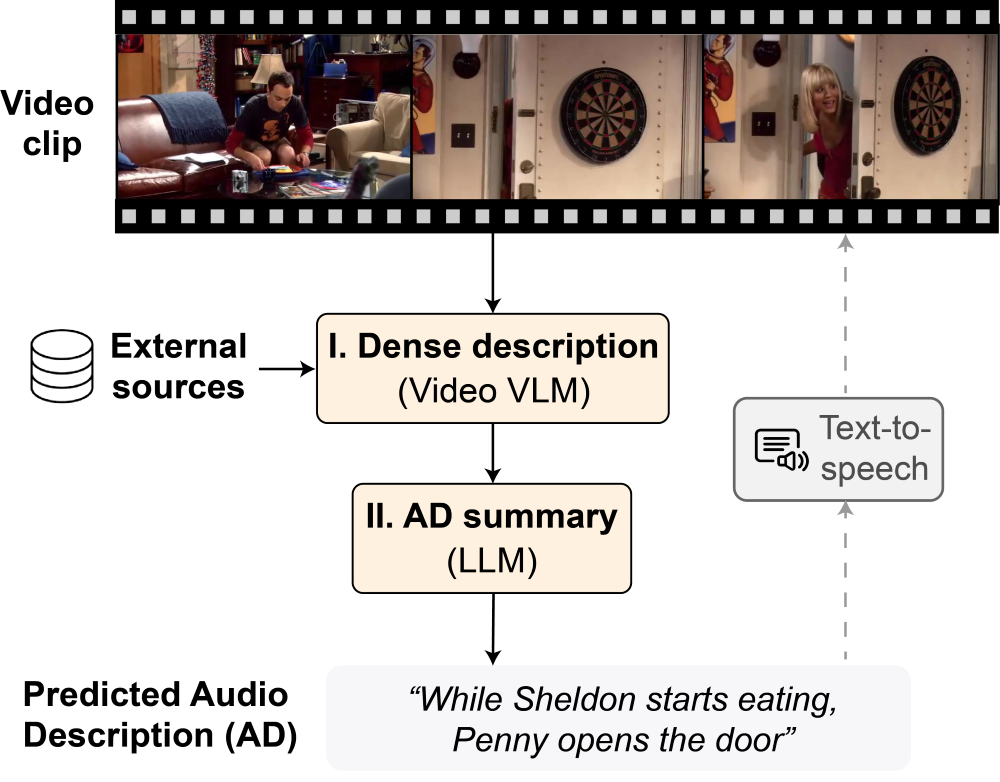
Junyu Xie, Tengda Han, Max Bain, Arsha Nagrani, Gül Varol, Weidi Xie, Andrew Zisserman In ACCV, 2024 ArXiv / Bibtex / Project page / Code / Dataset (TV-AD) In this paper, we propose AutoAD-Zero, which is a training-free framework aiming at zero-shot Audio Description (AD) generation for movies and TV series. The overall framework feature two stages (dense description + AD summary), with the character information injected by visual-textual prompting. |
|
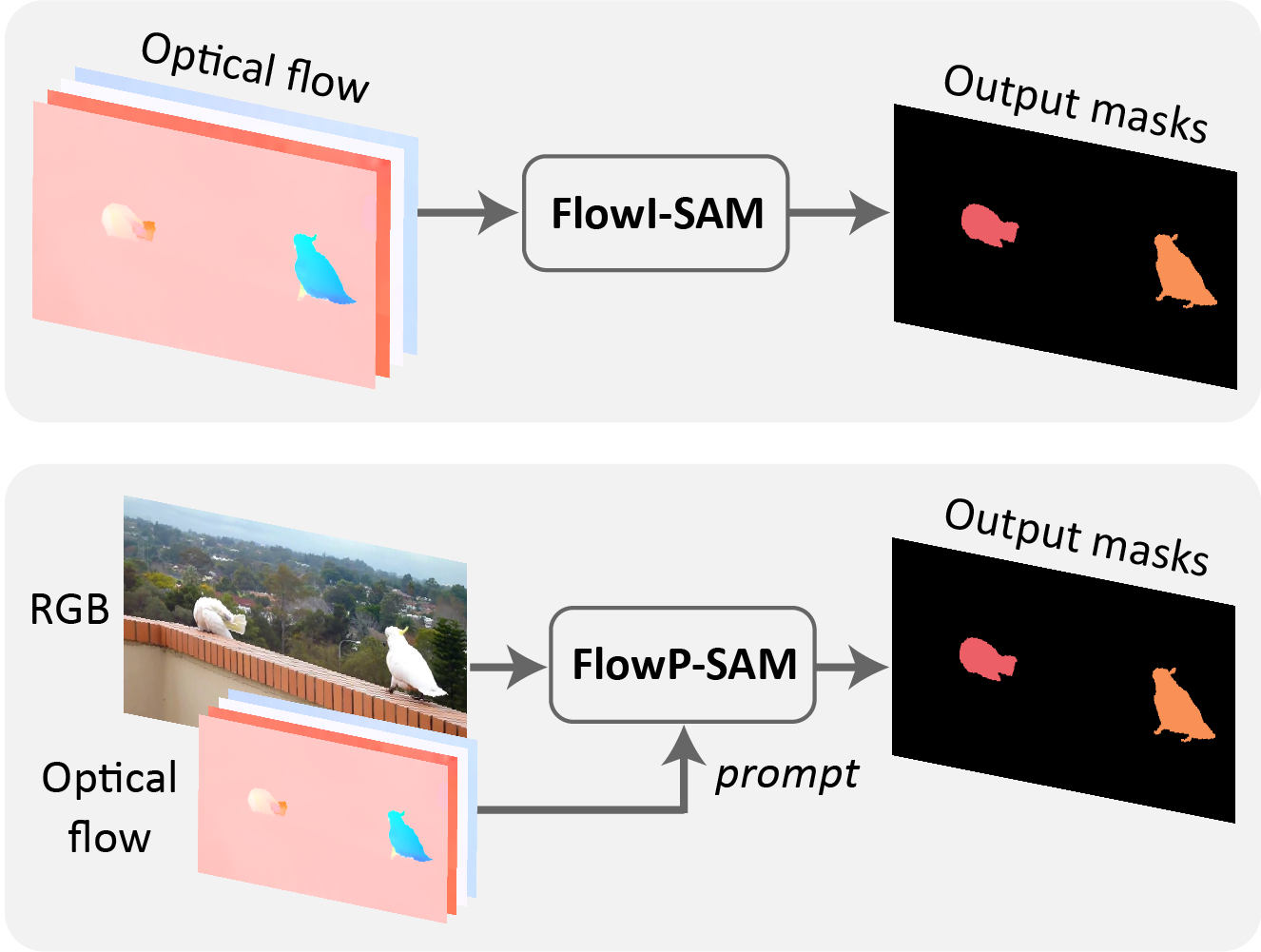
Junyu Xie, Charig Yang, Weidi Xie, Andrew Zisserman In ACCV (Oral), 2024 ArXiv / Bibtex / Project page / Code This paper focuses on motion segmentation by incorporating optical flow into the Segment Anything model (SAM), applying flow information as direct inputs (FlowISAM) or prompts (FlowPSAM). |
|
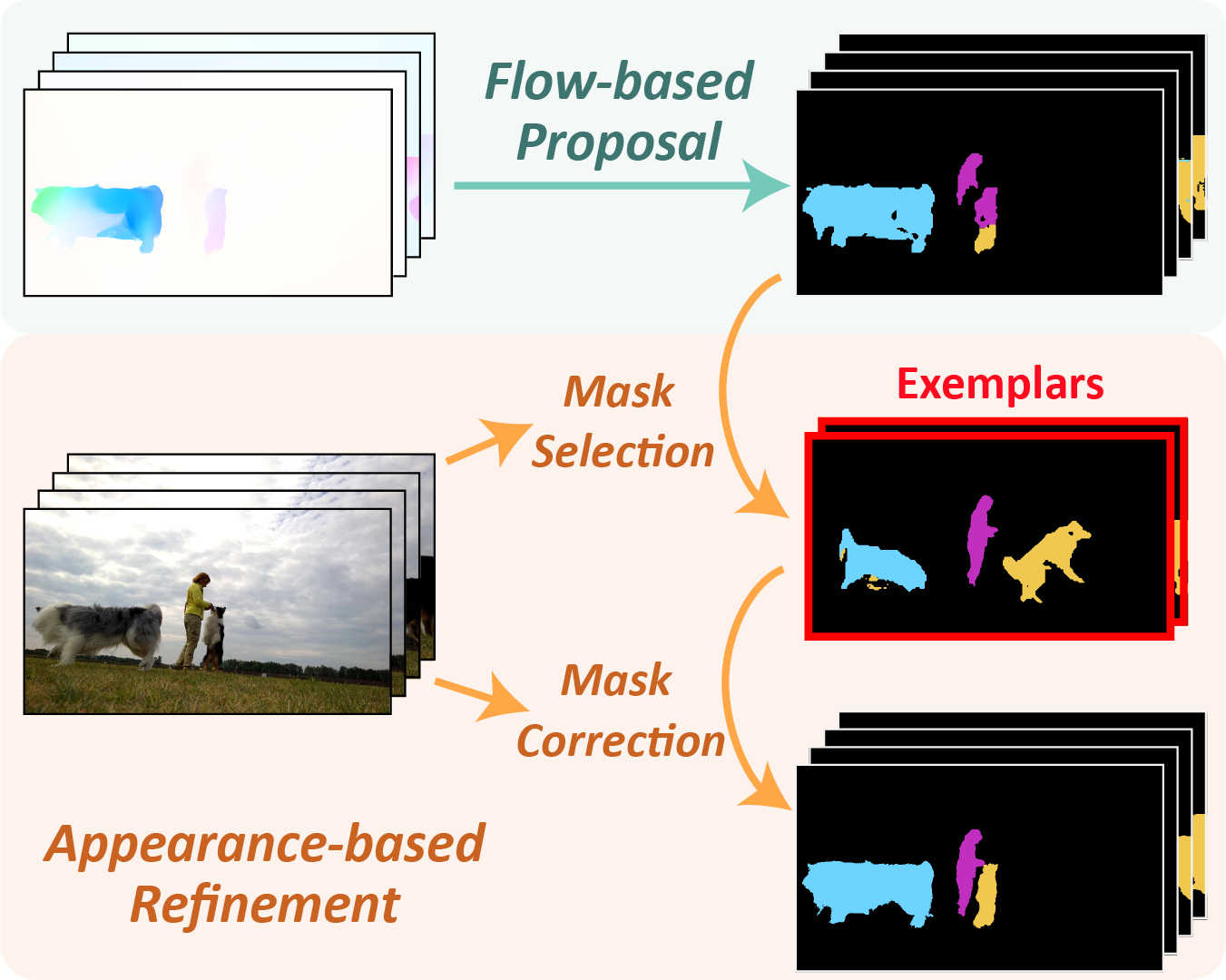
Junyu Xie, Weidi Xie, Andrew Zisserman In ECCV, 2024 ArXiv / Bibtex / Project page This paper aims at improving flow-only motion segmentation (e.g. OCLR predictions) by leveraging appearance information across video frames. A selection-correction pipeline is developed, along with a test-time model adaptation scheme that further alleviates the Sim2Real disparity. |
|
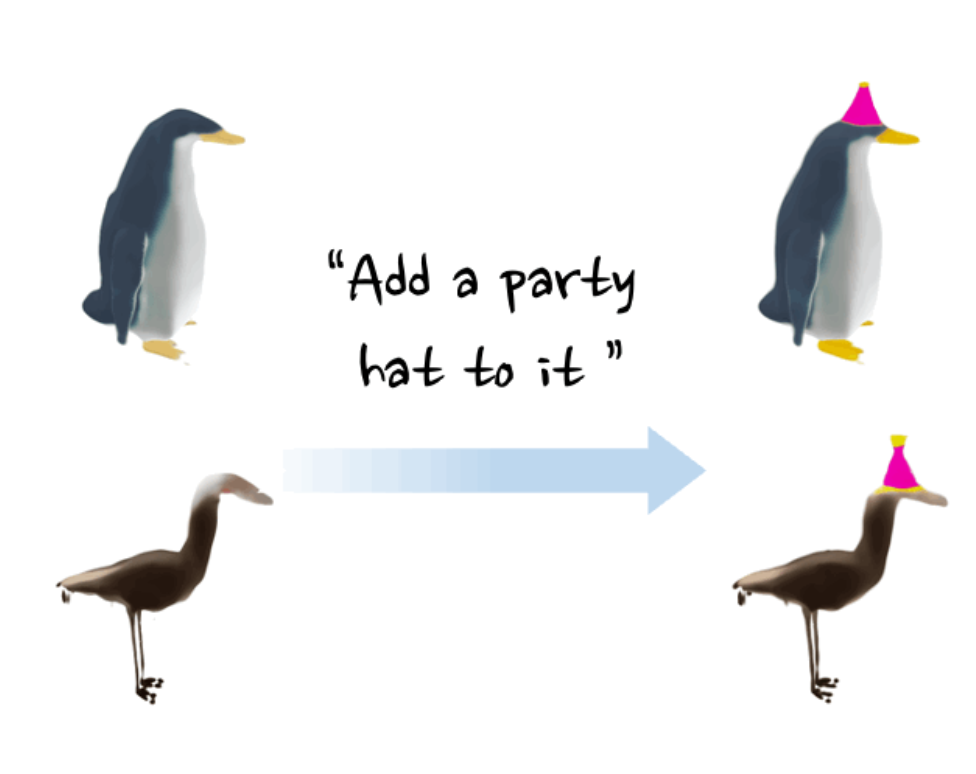
Minghao Chen, Junyu Xie, Iro Laina, Andrea Vedaldi In CVPR , 2024 ArXiv / Bibtex / Project page / Code / Demo This paper present a method, named SHAP-EDITOR, aiming at fast 3D editing (within one second). To acheve this, we propose to learn a universal editing function that can be applied to different objects in a feed-forward manner. |
|
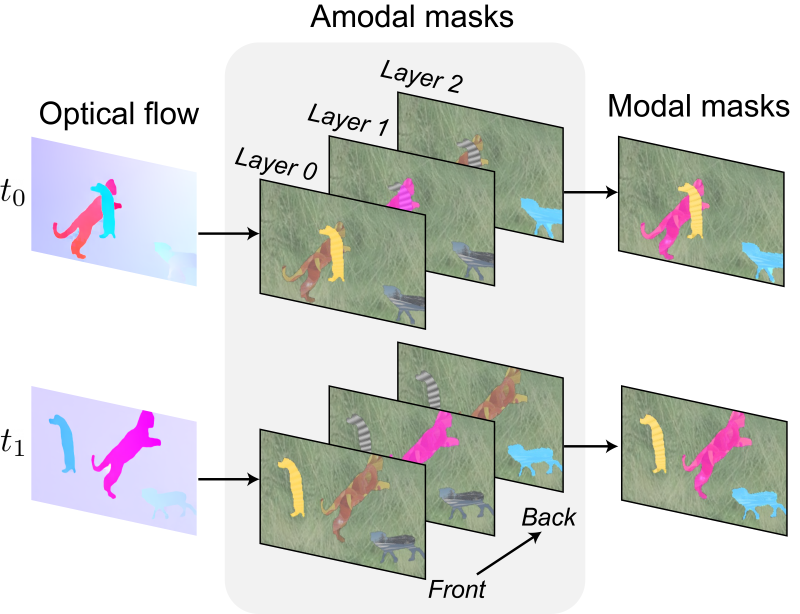
Junyu Xie, Weidi Xie, Andrew Zisserman In NeurIPS, 2022 ArXiv / Bibtex / Project page / Code In this paper, we propose the OCLR model for discovering, tracking and segmenting multiple moving objects in a video without relying on human annotations. This object-centric segmentation model utilises depth-ordered layered representations and is trained following a Sim2Real procedure. |
|
This website template is originally designed by Jon Barron. |